0 Comments
Approaching 20 years old, the Drupal Community must prioritize recruiting the next generation of Drupal Professionals
Time flies when you are having fun. One of those sayings I remember my parents saying that turned out to be quite true. My first Drupal experience was nearly 10 years ago and within a blink of an eye, we have seen enormous organizations adopt and commit to Drupal such as Turner, the Weather Channel, The Grammys, and Georgia.gov. Throughout the years, I have been very fortunate to meet a lot of Drupal community members in person but one thing I have noticed lately is that nearly everyone’s usernames can be anywhere between 10–15 years old. What does that mean? As my dad would say, it means we are getting O — L — D, old. For any thriving community, family business, organization, or your even favorite band for that matter, all of these entities must think about succession planning. Succession what, what is succession planning? Succession planning is a process for identifying and developing new leaders who can replace old leaders when they leave, retire or die. -Wikipedia That's right, we need to start planning a process for identifying who can take over in leadership roles that continue to push Drupal forward. If we intend to keep Drupal as a viable solution for large and small enterprises, then we should market ourselves to the talent pool as a viable career option to help in an attempt to lure talent to our community. There are many different way’s to promote our community and develop new leaders. Mentorship. Mentorship helps ease the barrier for entry into our community by providing guidance into how our community operates. Our community does have some great efforts taking place in the form of mentoring such as Drupal Diversity & Inclusion (DDI) initiative, the core mentoring initiative and of course the code and mentoring sprints at DrupalCon and DrupalCamps. These efforts are awesome and should be recognized as part of a larger strategic initiative to recruit the next generation of Drupal professionals. Companies spend billions of dollars a year in recruiting but as an open-source community, we don’t have billions so … what else can we do to attract new Drupal career professionals? 
The Drupal Career SummitThis year’s Atlanta Drupal Users’s Group (ADUG) decided to develop the Drupal Career Summit, all in an effort to recruit more professionals into the Drupal community. Participants will explore career opportunities, career development, and how open source solutions are changing the way we buy, build, and use technology.
When and Where Is it?On Saturday, September 14 from 1pm -4:30pm. Hilton Garden Inn Atlanta-Buckhead 3342 Peachtree Rd., NE | Atlanta, GA 30326 | LEARN MORE Who Should Attend?Student and job seekers can attend for FREE! The Summit will allow you to meet with potential employers and industry leaders. We’ll begin the summit with a panel of marketers, developers, designers, and managers that have extensive experience in the tech industry, and more specifically, the Drupal community. You’ll get a chance to learn about career opportunities and connect with peers with similar interests. REGISTERAre You Hiring?We’re looking for companies that want to hire and educate. You can get involved with the summit by becoming a sponsor for DrupalCamp Atlanta. Sponsors of the event will have the opportunity to engage with potential candidates through sponsored discussion tables and branded booths. With your sponsorship, you’ll get a booth, a discussion table, and 2 passes! At your booth, you’ll get plenty of foot traffic and a fantastic chance to network with attendees. BECOME A SPONSORWhat you can do?If you can’t physically attend our first Career Summit, you can still donate to our fundraising goals. And if you are not in the position to donate invite your employer, friends, and colleagues to participate. Drupal Career Summit. Drupal. The Next Generation. They Are Out There. was originally published in Drupal Atlanta on Medium, where people are continuing the conversation by highlighting and responding to this story. Originally from Drupal.org aggregator https://ift.tt/2LU0acG Pantheon is an excellent hosting service for both Drupal and WordPress sites. But to make their platform work and scale well they have set a number of limits built into the platform, these include process time limits and memory limits that are large enough for the vast majority of projects, but from time to time run you into trouble on large jobs. For data loading and updates their official answer is typically to copy the database to another server, run your job there, and copy the database back onto their server. That’s fine if you can afford to freeze updates to your production site, setup a process to mirror changes into your temporary copy, or some other project overhead that can be limiting and challenging. But sometimes that’s not an option, or the data load takes too long for that to be practical on a regular basis. I recently needed to do a very large import for records into a Drupal database and so started to play around with solutions that would allow me to ignore those time limits. We were looking at needing to do about 50 million data writes and the running time was initially over a week to complete the job. Since Drupal’s batch system was created to solve this exact problem it seemed like a good place to start. For this solution you need a file you can load and parse in segments, like a CSV file, which you can read one line at a time. It does not have to represent the final state, you can use this to actually load data if the process is quick, or you can serialize each record into a table or a queue job to actually process later. One quick note about the code samples, I wrote these based on the service-based approach outlined in my post about batch services and the batch service module I discussed there. It could be adapted to a more traditional batch job, but I like the clarity the wrapper provides for breaking this back down for discussion. The general concept here is that we upload the file and then progressively process it from within a batch job. The code samples below provide two classes to achieve this, first is a form that provides a managed file field which create a file entity that can be reliably passed to the batch processor. From there the batch service takes over and using a bit of basic PHP file handling to load the file into a database table. If you need to do more than load the data into the database directly (say create complex entities or other tasks) you can set up a second phase to run through the values to do that heavier lifting. To get us started the form includes this managed file:
$form['file'] = [
'#type' => 'managed_file',
'#name' => 'data_file',
'#title' => $this->t('Data file'),
'#description' => $this->t('CSV format for this example.'),
'#upload_location' => 'private://example_pantheon_loader_data/',
'#upload_validators' => [
'file_validate_extensions' => ['csv'],
],
];
The managed file form element automagically gives you a file entity, and the value in the form state is the id of that entity. This file will be temporary and have no references once the process is complete and so depending on your site setup the file will eventually be purged. Which all means we can pass all the values straight through to our batch processor: $batch = $this->dataLoaderBatchService->generateBatchJob($form_state->getValues()); When the data file is small enough, a few thousand rows at most, you can load them all right away without the need of a batch job. But that runs into both time and memory concerns and the whole point of this is to avoid those. With this approach we can ignore those and we’re only limited by Pantheon’s upload file size. If they file size is too large you can upload the file via sftp and read directly from there, so while this is an easy way to load the file you have other options. As we setup the file for processing in the batch job, we really need the file path not the ID. The main reason to use the managed file is they can reliably get the file path on a Pantheon server without us really needing to know anything about where they have things stashed. Since we’re about to use generic PHP functions for file processing we need to know that path reliably:
$fid = array_pop($data['file']);
$fileEntity = File::load($fid);
$ops = [];
if (empty($fileEntity)) {
$this->logger->error('Unable to load file data for processing.');
return [];
}
$filePath = $this->fileSystem->realpath($fileEntity->getFileUri());
$ops = ['processData' => [$filePath]];
Now we have a file and since it’s a csv we can load a few rows at time, process them, and then start again. Our batch processing function needs to track two things in addition to the file: the header values and the current file position. So in the first pass we initialize the position to zero and then load the first row as the header. For every pass after that we need to find point we left off. For this we use generic PHP files for loading and seeking the current location:
// Old-school file handling.
$path = array_pop($data);
$file = fopen($path, "r");
...
fseek($file, $filePos);
// Each pass we process 100 lines, if you have to do something complex
// you might want to reduce the run.
for ($i = 0; $i < 100; $i++) {
$row = fgetcsv($file);
if (!empty($row)) {
$data = array_combine($header, $row);
$member['timestamp'] = time();
$rowData = [
'col_one' => $data['field_name'],
'data' => serialize($data),
'timestamp' => time(),
];
$row_id = $this->database->insert('example_pantheon_loader_tracker')
->fields($rowData)
->execute();
// If you're setting up for a queue you include something like this.
// $queue = $this->queueFactory->get(‘example_pantheon_loader_remap’);
// $queue->createItem($row_id);
}
else {
break;
}
}
$filePos = (float) ftell($file);
$context['finished'] = $filePos / filesize($path);
The example code just dumps this all into a database table. This can be useful as a raw data loader if you need to add a large data set to an existing site that’s used for reference data or something similar. It can also be used as the base to create more complex objects. The example code includes comments about generating a queue worker that could then run over time on cron or as another batch job; the Queue UI module provides a simple interface to run those on a batch job. I’ve run this process for several hours at a stretch. Pantheon does have issues with systems errors if left to run a batch job for extreme runs (I ran into problems on some runs after 6-8 hours of run time), so a prep into the database followed by running on queue or something else easier to restart has been more reliable. Originally from Drupal.org aggregator https://ift.tt/318sw6B
Best of July: Top 5 Drupal Blog Posts that We Have Bookmarked this Month
 It's that time of the month again! The time when we express our thanks to those Drupal teams who've generously (and altruistically) shared valuable free content with us, the rest of the community. Content with an impact on our own workflow and our Drupal development process. In this respect, as usual, we've handpicked 5 Drupal blog posts, from all those that we've bookmarked this month, that we've found most “enlightening”. From: Originally from Drupal.org aggregator https://ift.tt/2STWh8r
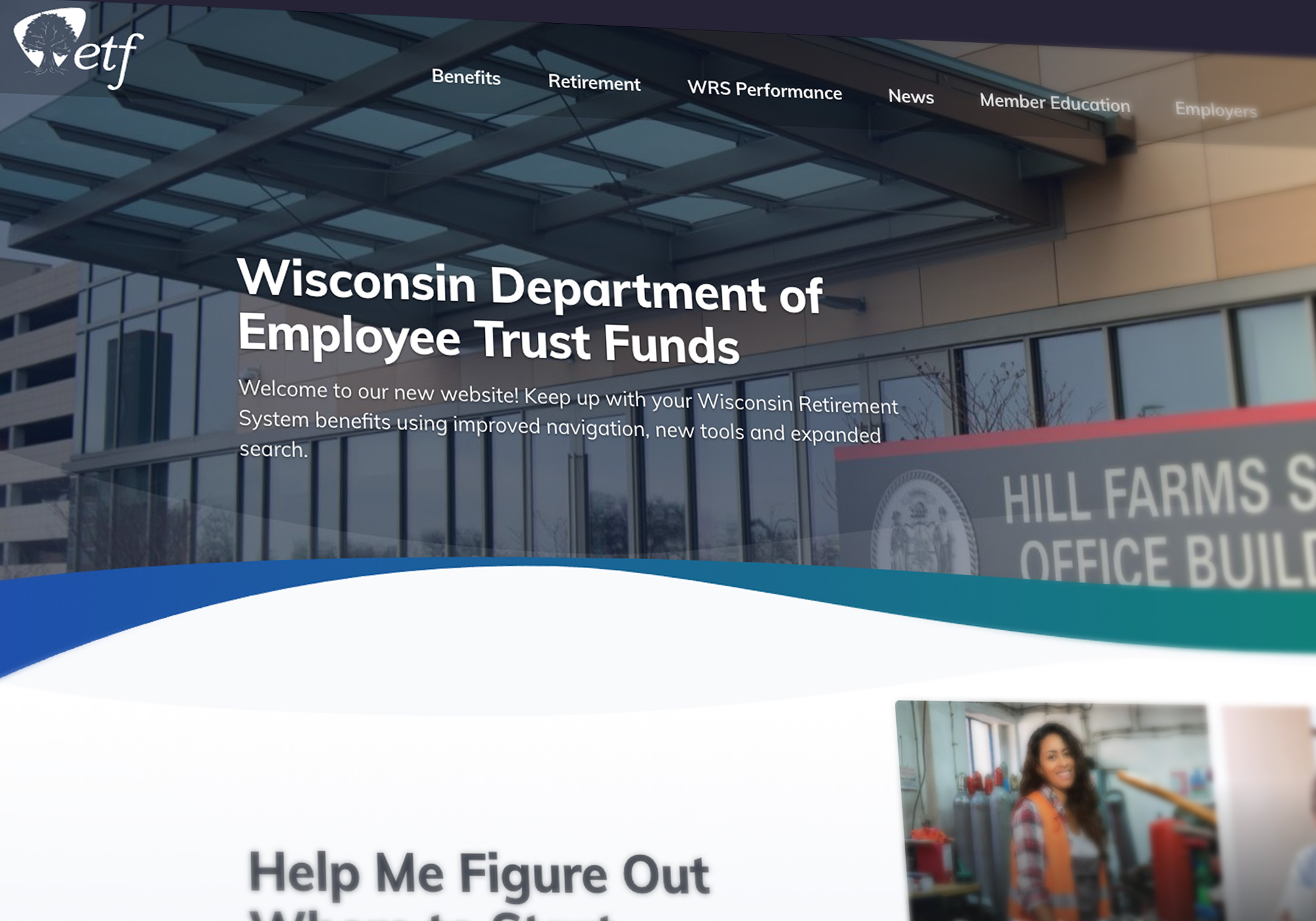
Re-platforming the Wisconsin Department of Employee Trust Funds website from HTML templates to Drupal 8, including a complete visual and user experience redesign. etf.wi.gov An Effortless Customer Experience for Wisconsin Government Employees, Retirees, and Employers OnThe Wisconsin Department of Employee Trust Funds (ETF) is responsible for managing the pension and other retirement benefits of over 630,000 state and local government employees and retirees in the state of Wisconsin. With approximately $98 billion in assets, the Wisconsin Retirement System is the 8th largest U.S. public pension fund and the 25th largest public or private pension fund in the world. In addition to overseeing the Wisconsin Retirement System, ETF also provides benefits such as group health insurance, disability benefits, and group life insurance. Over a half-million people rely on the information ETF provides in order to make decisions that impact not only themselves, but their children, and their children’s children. The ChallengeGiven the extent of services provided by ETF, their website is large and complex with a wealth of vital information. When ETF first approached Palantir.net, their website (shown) hadn't been updated since the early 2000s, and it lacked a content management system. The site wasn’t accessible, it wasn’t responsive, and its overall user experience needed a drastic overhaul. Simply put, Wisconsin government employees could not easily navigate the crucial information they need to understand and make decisions about the benefits that they earn.
Key OutcomesETF engaged Palantir to re-platform their website from HTML templates to the Drupal 8 content management system, including a complete visual and user experience redesign. After partnering with Palantir, the new user-friendly ETF site:
Upgrade to the Employee Benefits ExplorerOne of the most notable features of the new site is ETF’s Benefits Explorer. An important function of the ETF site is offering information regarding pension, health insurance, and other benefits. On ETF’s old site, employees were required to select cumbersome and confusing benefit options before they could find detailed information about their benefits. This task was made even more difficult by the fact that the names of benefit options are not descriptive or intuitive. ETF’s previous solution was to send physical mailers with distinctive photos on the covers, and then direct visitors to the website to select the benefit options that had the same image as their mailer. Palantir and ETF knew that the “find my benefits” user experience needed a complete overhaul. In our initial onsite, we identified a potential solution: creating a database of employers and the benefit options they offer. With this list we built a benefits explorer tool that allows ETF’s customers to search for benefits by the one piece of information they will always definitely have: the name of their employer. 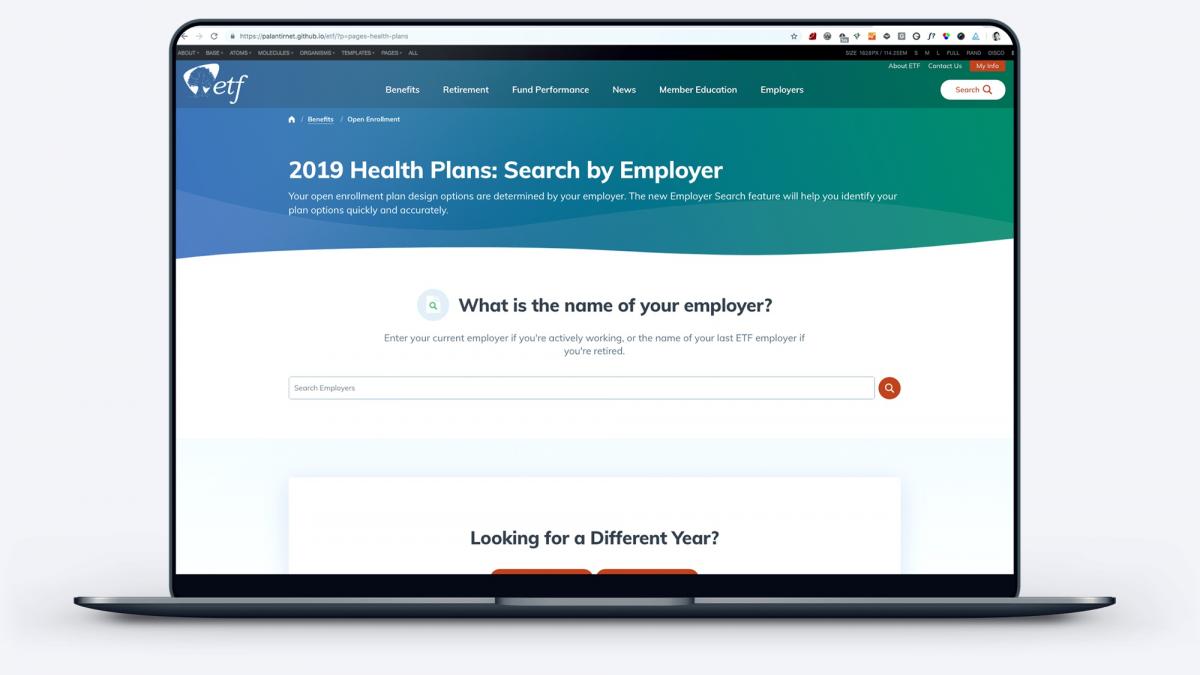 With the new explorer experience, site visitors begin by typing in the name of their employer and are immediately provided with their benefit options. We built two versions of the tool: one for the specific task of identifying health plan options, which are typically decided once a year during open enrollment, and one for identifying all benefits offered by your employer, which can be used any time of year. The new “My Benefits” explorer is now the second most visited page on the new ETF site, which shows just how helpful this new feature is for ETF’s customers. How We Did ItIn order to transform the ETF website into an effortless experience for Wisconsin government employees, retirees, and employers, there were five critical elements to consider. Our approach involved:
Identifying “Top Tasks” The biggest negative factor of the previous ETF site’s user experience was its confusing menus. The site presented too many options and pathways for people to find information such as which health insurance plan they belong to or how to apply for retirement benefits, and the pathways often led to different pages about the same topic. Frequently, people would give up or call customer support, which is only open during typical business hours. Palantir knew the redesign would have the most impact if the site was restructured to fit the needs of ETF’s customers. In order to guarantee we were addressing customers’ most important needs, we used the Top Task Identification methodology developed by customer experience researcher and advocate Gerry McGovern. Through the use of this method, we organized ETF’s content by the tasks site users deemed most important, with multiple paths to get to content through their homepage, site and organic search, and related content. Revising Content Our goal was to make content findable by both internal and external search engines. No matter what page a visitor enters the site on, the page should make sense and the visitor should be able to find their way to more information. While the Palantir team was completing the Top Tasks analysis, the internal ETF team revised the website content by focusing on:
User-tested Information Architecture (IA) Once we had the results from our Top Tasks study, we worked toward designing a menu organized intuitively for customers. In our initial onsite, we conducted an open card sort with about 40 ETF stakeholders. Our goal was to have the ETF site content experts experiment with ways to improve the labelling, grouping, and organization of the content on their site. We divided the stakeholders into six teams of five and gave them a set of 50 cards featuring representative content on their site. The ideas our teams generated fell largely into two groups:
When we came back together as a group, our team of 40 stakeholders agreed that exploring a task-based information architecture would be worthwhile, but there was significant concern that switching away from an audience-based IA would confuse their customers. Since making the site easy to use was one of our top project goals, our teams agreed to a rigorous IA testing approach. We agreed to conduct two rounds of tree tests on both an audience-oriented and task-oriented IA, and conduct three additional rounds of tests to refine the chosen approach. Ultimately, our tests showed that the most intuitive way to organize the content for ETF’s range of customers was to organize by task, with one significant exception: Employers. ETF serves the human resources teams of all state of Wisconsin employers, and those users had completely separate content requirements from those of government employees and retirees. 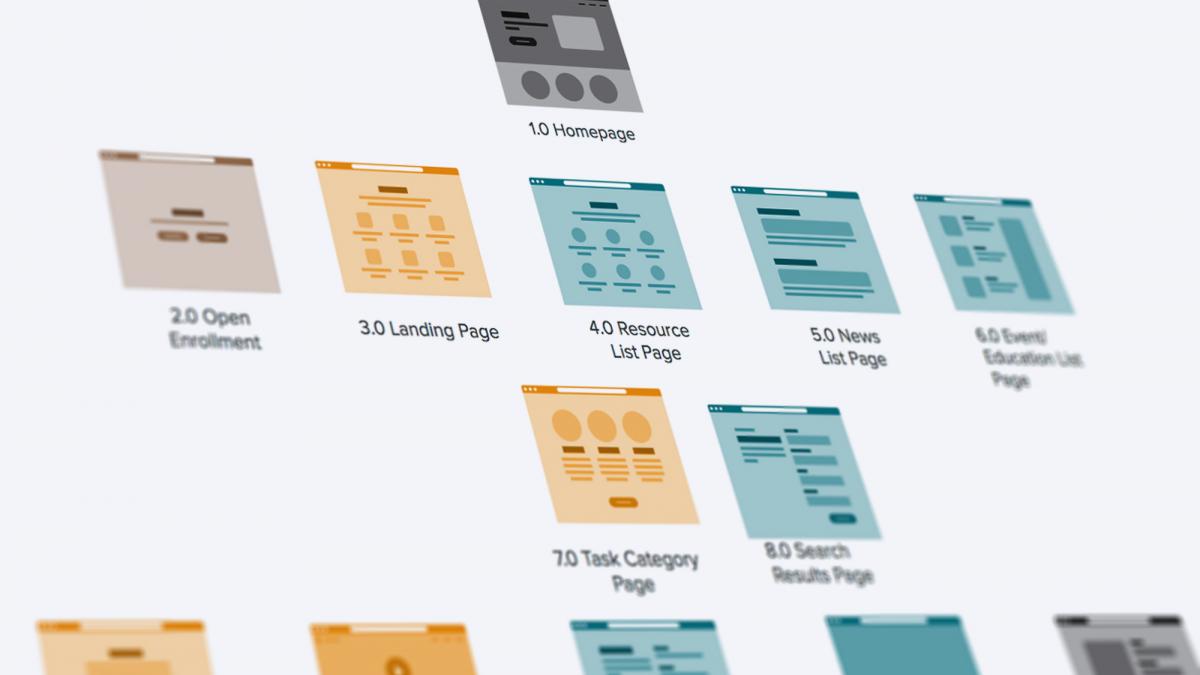 Responsive Design System on DrupalBecause the former ETF site was significantly outdated, it completely lacked a content model, and the site itself was a massive hodgepodge of design elements. Palantir identified key ETF user flows, matched the content to each flow, and then abstracted out templates to serve each flow. The overarching goal of this design system is to create intuitive, repeatable user flows through the website. These patterns enable visitors to quickly scan for the information they need, and make quick decisions about where to go next. Accessibility and responsiveness are core requirements for ETF. Palantir used the a11y checklist from the very beginning of our design process, and continuously tested our visual designs for font size, color contrast, and general spacing of elements to ensure that accessibility was built into our design rather than retrofitted at the end. We also conducted usability tests with real users, which helped us make accessibility improvements that accessibility checkers missed. In addition, the new design system is also fully responsive, which enables ETF’s customers to access the site from any device. Robust Content Management In addition to the efficiencies gained for site visitors, the new Drupal 8 site streamlines the content management process for the internal ETF site admin team. Previously, content creation happened across people and departments with minimal editorial guidelines. Once the copy was approved internally, the new content was handed to the webmaster for inclusion on the site. The process for updating content frequently took weeks. With their new Drupal 8 platform, the ETF team has moved to a distributed authorship workflow, underpinned by the Workbench suite of modules which allows for editorial/publishing permissions. Now, ETF subject matter experts can keep their own content up to date while following established standards and best practices. The decision to publish content is still owned by a smaller group, to ensure that only approved and correct content is uploaded to the live site. 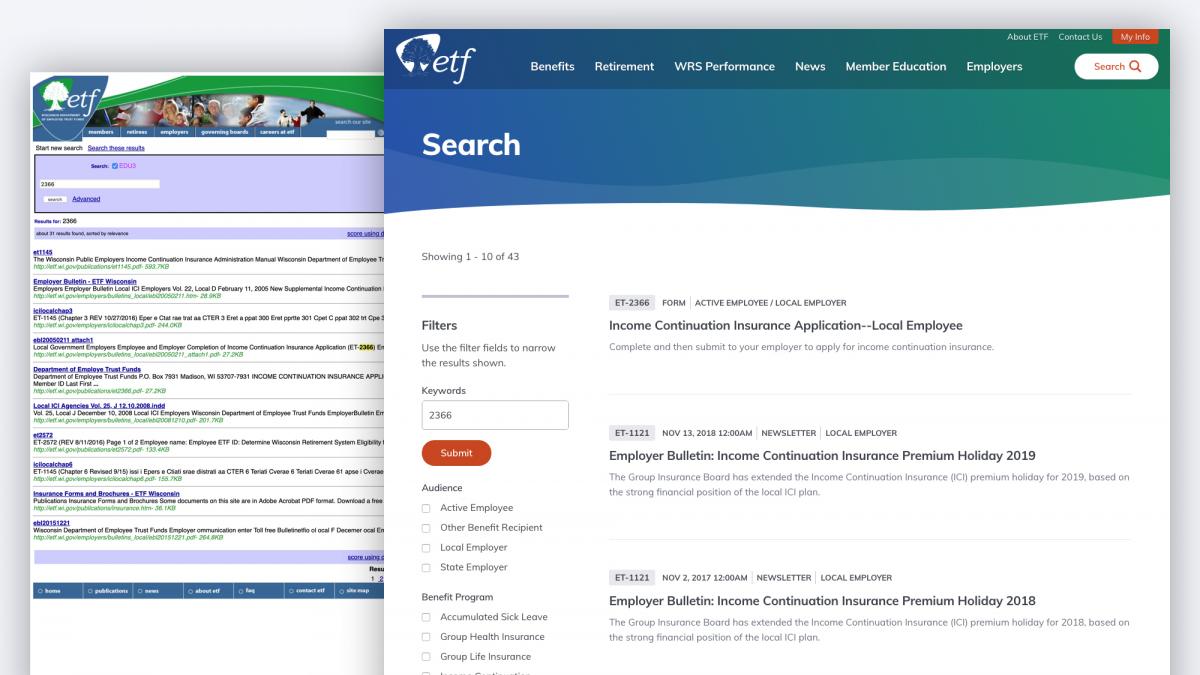 The ResultsWith the fully responsive design system in place, the new ETF site offers a significantly upgraded user experience for their customers:
Originally from Drupal.org aggregator https://ift.tt/2Ki6LKz  Testing integrations with external systems can sometimes prove tricky. Services like Acquia Lift & Content Hub need to make connections back to your server in order to pull content. Testing this requires that your environment be publicly accessible, which often precludes testing on your local development environment. Enter ngrok As mentioned in Acquia's documentation, ngrok can be used to facilitate local development with Content Hub. Once you install ngrok on your development environment, you'll be able to use the ngrok client to connect and create an instant, secure URL to your local development environment that will allow traffic to connect… Testing integrations with external systems can sometimes prove tricky. Services like Acquia Lift & Content Hub need to make connections back to your server in order to pull content. Testing this requires that your environment be publicly accessible, which often precludes testing on your local development environment. Enter ngrok As mentioned in Acquia's documentation, ngrok can be used to facilitate local development with Content Hub. Once you install ngrok on your development environment, you'll be able to use the ngrok client to connect and create an instant, secure URL to your local development environment that will allow traffic to connect…Originally from Drupal.org aggregator https://ift.tt/2LPoqwA I posted my analysis of top uses of deprecated code in Drupal contributed projects in May 2019 two months ago. There are some great news since then. First of all, Matt Glaman of Centarro implemented support for deprecation messages directly in reports, so we can analyse reports much better in terms of actionability. Second, Ryan Aslett at the Drupal Association implemented running all-contrib deprecation testing on drupalci.org (Drupal's official CI environment). While showing that data on projects themselves is in the works, I took the data to crunch some numbers again and the top deprecated API uses are largely the same as two months ago. However, we have full analysis of all deprecation messages and their fixability which gets us two powerful conclusions. Stop using drupal_set_message() now!If there is one thing you do for Drupal 9 compatibility, make it getting rid of using Of the total of 23750 deprecated API use instances found in 7561 projects, 29% of them were instances of Dezső Biczó already built automated deprecation fixers covering 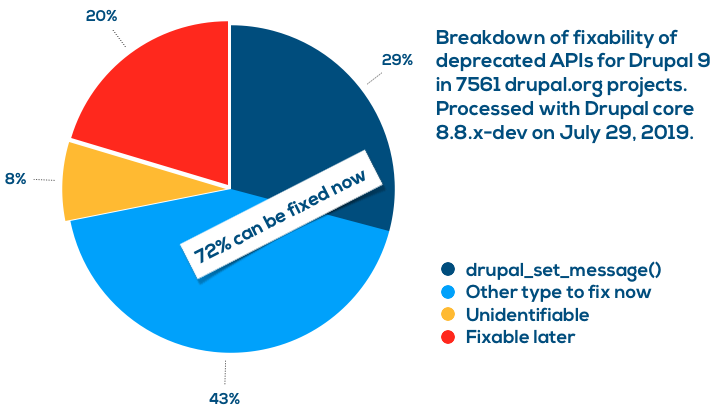 72% of deprecated API use can already be resolvedOn top of the 29% of Upgrade Status is a nice visual tool to explicitly list all the errors in the projects you scan. It provides instructions on how to fix them and immediately fixable issues are highlighted. Work with project maintainersYou are not a drupal.org project maintainer but want to help? Yay! Based on the above it may be tempting to run to the issue queue and submit issues for fixing all the things. Good plan! One thing to keep in mind though is to work with the maintainers of projects so your help benefits the project most effectively. Drupal.org project owners may specify Drupal 9 plan information that should help you engage with them the best way (use the right meta issue, know of their timeline plans, and so on). Check the project page of projects you are interested to be involved with to make sure you contribute the best way.
More to comeI think the data is super-interesting and I plan to do more with it, for example cross-referencing with project usage. Stay tuned for more information in the future. In the meantime all the source data is available for your mining as well. Disclaimer: The data is based on the state of contributed projects on July 29, 2019 based on Drupal core's 8.8.x development branch on July 29, 2019. As contributed module maintainers commit fixes, the data will get better. As core introduces more deprecations (until Drupal 8.8.0-alpha1), the data could get worse. There may also be phpstan Drupal integration bugs or missing features, such as not finding uses of deprecated global constants yet. This is a snapshot as the tools and state of code on all sides evolve, the resulting data will be different. Originally from Drupal.org aggregator https://ift.tt/2GAzhq0
|
AuthorWrite something about yourself. No need to be fancy, just an overview. Archives
April 2023
Categories |
 RSS Feed
RSS Feed
